3W - 데스티네이션 룰을 활용한 네트워크 복원력
개요
이번 문서에서는 네트워크 복원력을 위한 각종 세팅 방법들을 알아본다.
주로 보는 설정은 DestinationRule일 텐데, 그렇다고 해서 모든 네트워크의 안정성을 위한 세팅이 데룰로 이뤄지는 것은 아니다.
사전 지식
thundering herd
한 포인트로 여러 입력이 무리지어 폭주하듯이 밀려들어서 문제가 발생하는 것을 컴퓨터 과학에서는 thundering herd(폭주하는 무리)라고 표현한다.[1]
이 표현은 다양한 곳에서 활용된다.
- 로드밸런싱에서 한 곳으로 부하가 몰리는 상황 - 우리가 다루고 있는 문제!
- 멀티 쓰레드 환경에서 락이 걸린 자원에 대해 해제되자마자 모든 쓰레드가 자신이 가져가겠답시고 경합하는 상황
- 캐시되고 있던 정보가 한꺼번에 무효화되었을 때 데이터를 다시 가져오겠다고 여러 클라가 요청을 보내는 상황
각 상황마다 나오는 결과는 다를 수 있지만, 아무튼 이렇게 병목이 발생하게 되는 원인 현상을 통틀어 thundering herd라 부르는 것이다.
이 용어가 간혹 등장할 거라 미리 다룬다.
네트워크 복원력
네트워크 상의, 혹은 어플리케이션 단에 문제가 발생했을 때 실제 서비스의 장애를 최소화하며 가능한 알아서 이를 회복하는 것을 네트워크 복원력(network resilience)이라고 한다.
마이크로서비스 아키텍처에서는 시스템 분산을 통해 하나의 장애가 전체 서비스로 이어지지 않도록 할 수 있다.
그러나 한편 이것은 장애가 터질 포인트를 많이 만들 수 있다는 말이기도 하기에, 가능한 MSA에서는 자동으로 문제가 있을 때 복원할 수 있는 복원력 패턴을 세팅할 필요가 있다.
그렇다면 어떤 식으로 전략을 구상할 수 있을까?
가령 A 서비스가 클라, B 서비스가 서버로서 통신을 하는 상황이라고 하고 여기에서 원인은 모르지만 문제가 발생한다고 쳐보자.
- 에러가 간헐적이라면 단순히 A에서 재시도 횟수를 늘리는 식으로 대응할 수 있다.
- 그러나 재시도를 늘리는 것은 B서비스의 부하를 야기하여 더 안 좋은 상황을 만들게 될 수도 있다.
- 아예 통신이 안 되는 거라면 B 서비스로는 트래픽을 아예 보내지 않는 식으로 대응할 수 있다.
- 이 경우 여러 복제 B서비스를 세팅해두지 않았다면 문제가 되나, 여러 레플리카가 있는 상황이라면 문제가 되는 서비스 하나만 잠시 제외시키는 건 매우 효과적인 방식이다.
- 참고로 쿠버네티스에서도 기본적으로 이 기능이 있는데, 파드의 레디 상태를 기반으로 서비스의 엔드포인트를 제거하는 식이다.
이밖에도 트래픽 레이턴시가 지나치게 길다면 아예 일정 시간을 넘기면 에러로 간주한다던가 하는 다양한 전략을 채택할 수 있다.
서비스 메시가 활성화되기 이전, 이러나 복원력을 위한 세팅은 코드 단에서 이뤄지곤 했다.
당연히 이것은 서비스 메시 도입 이전의 문제와 마찬가지의 문제를 낳았다.
땡스 투 엔보이, 엔보이는 어플리케이션의 네트워크 능력을 책임지는 프록시로서! 관련한 많은 전략을 채택할 수 있도록 기능을 제공하고 있다.
이번에는 이스티오에서 이 복원력 패턴을 구현하는 것이 목적이다.
이스티오에서 설정할 수 있는 대표적인 네트워크 복원력 세팅은 다음과 같다.
- 클라이언트 측 로드 밸런싱 Client-side load balancing
- 지역 인식 로드 밸런싱 Locality-aware load balancing
- 타임아웃 및 재시도 Timeouts and retries
- 서킷 브레이킹 Circuit breaking
클라이언트 로드밸런싱
로드밸런싱이면 로드밸런싱이지 클라 로밸은 또 뭐냐?
보통의 로드밸런서는 여러 서비스 앞단에 위치해서 클라의 요청을 분산하는 식으로 동작한다.
그러나 이런 서비스 앞단에 무언가 위치하지 않고 클라이언트 측에서 알아서 여러 서비스에 분산해서 요청을 보내면 이것이 바로 클라이언트 로드밸런싱이다.
서비스 레지스트리로부터 각각 업스트림 호스트림 정보를 받아서 관리하는 이스티오에서는 이 방식이 매우 제격이라 할 수 있다.
클라이언트 로드밸런싱 방식은 단일 로드밸런서를 두지 않기에 단일 장애 지점이 없다는 장점이 있다.
least request 로드밸런싱
그러나 위처럼 오히려 문제가 발생하는 케이스도 있다는 것을 염두해야 한다.
초록 클라이언트가 최소 연결(least connected) 기반 로드밸런싱 알고리즘을 쓰고 있다고 생각해보자.
이 클라이언트는 현재 서버 2,3에 tcp 연결을 해둔 상태이기에 서버 1이 최소 연결됐다고 생각하고 서버 1로 트래픽을 보내게 될 것이다.
그러나 실상 서버 1은 트래픽 부하를 받고 있는 상태일 수도 있는 것이다!
트래픽 부하를 줄이기 위해 로드밸런싱을 하는데 오히려 부하가 일어나고 있는 곳으로 트래픽을 보내버리는 오동작을 할 수도 있다는 사실을 염두해야 한다.
이런 문제가 발생하는 이유는 클라이언트 측에서 로드밸런싱을 하기 때문이다.
보통 최소 연결의 기준은 tcp 커넥션 풀에 차있는 연결 개수를 기준으로 한다.
서버 측 로드밸런싱의 경우 서비스들의 앞단에 위치한 로드밸런서가 이 커넥션 풀을 서비스들과 연결하고 있기 때문에 어떤 서버가 적게 요청을 받고 있는 정확하게 파악할 수 있다.
그러나 클라이언트 로드밸런싱에서는 각 클라이언트가 자신의 커넥션 풀을 기반으로 최소 연결 여부를 판단한다.
그래서 위와 같은 문제가 발생할 수 있는 것이다.
그래서 애초에 엔보이에서는 자신들의 최소 연결 로드밸런싱 방식을 아예 least request 로드밸런싱이라고 부른다.[2]
근데 굳이 이스티오는 헷갈리게 해당 로드밸런싱 정책 이름을 LEAST_CONN이라고 해돴다
말 그대로 트래픽을 보내는 입장에서 최소로 요청을 보낸 곳으로 요청을 보내는 방식이라는 것을 명확히 하는 표현이다.
여기에 추가적으로, least request를 수행할 때 엔보이는 사실 전체 업스트림 중에서 가장 적은 활성 요청이 이뤄지는 업스트림으로 트래픽을 보내지 않는다!
정확하게는 전체 M개의 업스트림 중 무작위로 N개(기본값은 2개)를 고른 다음에 이 중에서 요청이 적은 쪽으로 트래픽을 보낸다.
이 방식을 power of two choices라고 표현하는데, 전체 M개를 순회하면서 가장 요청이 적은 것을 찾는 시간이 오래 걸리기 때문에 샘플링을 해서 근사적으로 최소 연결을 하는 것이다.
참고로 power of two choices는 기본적으로 직관적이면서 밸런싱 결정 속도가 빠른 한편 랜덤 밸런싱보다 성능이 월등하다고 증명됐다.[3]
영상으로 보면 더 직관적으로 이걸 확인할 수 있다.[4]
지역 기반 로드밸런싱
locality-aware 로드밸런싱은 말 그대로 최대한 가까운 지역으로 트래픽을 보내는 것을 말한다.
어느 환경에서든 트래픽의 지연은 비용과 효율에서 심각한 문제를 야기하기 때문에 이러한 설정은 매우 중요한 운영 전략 중 하나이다.
자세한 설명은 데스티네이션 룰 부분에서 다루겠다.
DestinationRule이란?
데스티네이션 룰은 라우팅될 목적지, 즉 클러스터에 대한 규칙을 작성하는 리소스이다.
버츄얼 서비스가 라우팅에 대한 설정을 명시했다면, 데룰은 버츄얼 서비스의 목적지로서 라우팅 후 관련한 설정을 명시한다.
목적지에 대한 규칙을 지정한다 해서 이름도 Destination Rule인 것이다!
- 서브셋 분할
- 하나의 클러스터로 묶인 엔드포인트들을 여러 부분집합으로 나눌 수 있다.
- 가령 한 서비스에 버전이 2개가 있는 상황일 때, 이것을 나누어 상세하게 라우팅할 수 있도록 정보를 제공하게 만들 수 있다.
- 트래픽 정책
- 로드밸런싱 정책을 설정할 수 있다.
- 이때 클러스터로 트래픽을 보낼 클라이언트 측 엔보이에 세팅이 되는 거라, 이런 방식을 클라이언트 로드밸런싱이라고 따로 부르기도 한다.
- 지역성(locality) 트래픽 로드 밸런싱도 가능하다.
- 서킷 브레이커로서 문제가 있는 호스트에 대해 트래픽이 가지 않도록 설정하는 것도 여기에서 진행된다.
- 트래픽 연결을 유지하는 커넥션 풀(connection pool) 설정
- 어떤 트래픽이 문제 있는 트래픽인지, 이상치 탐지(outlier detection)
- 로드밸런싱 정책을 설정할 수 있다.
- 통신 간 암호화
- 터널 세팅
이렇게 목적지를 세팅하는 행위는 네트워크 복원력(resilency), 혹은 서킷 브레이커 기능을 넣는 것과 같다.
가령 건강하지 않은 엔드포인트에는 트래픽을 보내지 않고, 레이턴시가 너무 긴 엔드포인트는 트래픽을 적게 보낸다던가 하는 식의 전략을 수립할 수 있는 게 바로 데스티네이션 룰이다.
데스티네이션 룰 동작
버츄얼 서비스와 달리 클러스터에 대한 설정을 하는 만큼, 설정 대상이 되는 엔보이를 찾는 작업이 조금 다르다.
일단 데룰은 서비스 레지스트리에 등록된 호스트를 기반으로 설정이 이뤄진다.
그 다음 이 클러스터 설정에 영향을 받을 엔보이를 탐색한다.
hosts필드를 토대로 서비스 레지스트리에서 대상이 될 업스트림 클러스터를 정한다.- 해당 클러스터를 가지고 있는 모든 엔보이에 대해 관련 CDS 설정을 적용한다.
양식 작성법
apiVersion: networking.istio.io/v1
kind: DestinationRule
metadata:
name: bookinfo-ratings
spec:
host: ratings.prod.svc.cluster.local
workloadSelector:
matchLabels:
app: ratings
trafficPolicy:
loadBalancer:
simple: LEAST_REQUEST
subsets:
- name: testversion
labels:
version: v3
trafficPolicy:
loadBalancer:
simple: ROUND_ROBIN
기본 필드 몇 개는 버츄얼 서비스와 비슷하다.
일단 hosts 필드를 지정하는데, 이 값은 서비스 레지스트리에 등록된 값이어야 한다.
이 값은 버츄얼 서비스와 마찬가지로 FQDN으로 두는 게 좋다.
subsets
subsets:
- name: version1
labels:
version: 1
- name: version2
labels:
version: 2
클러스터를 부분집합으로 나눌 때 사용하는 필드로, 라벨 셀렉터 기반으로 세부 집합을 나눈다.
보통 version 라벨을 설정해야 나중에 Kialli로도 보기 좋다.
trafficPolicy
trafficPolicy:
loadBalancer:
simple: ROUND_ROBIN
tls:
credentialName: client-credential
mode: MUTUAL
트래픽 정책을 적용하는 필드로, 여기에 다양한 설정을 넣을 수 있다.
loadBalancer
loadBalancer:
simple: ROUND_ROBIN
로드밸런싱 세팅을 하는 필드이다.
- simple - 간단한 로드밸런싱 알고리즘을 적용할 때 사용하는 필드
- UNSPECIFIED - 이스티오가 알아서 설정!
- RANDOM
- PASSTHROUGH - 업스트림에 로드밸런싱 위임..즉 아무것도 안 함!
- ROUND_ROBIN
- LEAST_REQUEST - 요청이 적은 업스트림으로 많이 보내며, 일반적으로는 가장 좋다.
localityLbSetting
loadBalancer:
simple: ROUND_ROBIN
localityLbSetting:
enabled: true
# 정적으로 분산 비율 지정
distribute:
- from: us-west/zone1/*
to:
"us-west/zone1/*": 80
"us-west/zone2/*": 20 # 합은 무조건 100이 돼야 하며, 명시되지 않은 지역으로는 트래픽이 가지 않는다.
- from: us-west/zone2/*
to:
"us-west/zone1/*": 20
"us-west/zone2/*": 80
---
# 한 지역이 실패 시 보낼 다른 지역 지정
failover:
- from: us-west
to: us-east
- from: us-east
to: eu-central
---
# 실패 시 가까운 지역을 매기는 순서
failoverPriority:
- "topology.istio.io/network"
- "topology.kubernetes.io/region"
- "topology.kubernetes.io/zone"
- "topology.istio.io/subzone"
지역적 로드밸런싱 세팅을 하는 필드로, 메시 전역적인 설정을 덮어쓰기한다.
클라우드 환경에서든, 멀티 클러스터 환경에서든 지역성 세팅을 해주는 것은 비용과 효율 측면에서 매우 중요하다.
이스티오에서는 {리전}/{존}/{서브존} 형태로 지역을 분류하는데, 쿠버네티스의 well-known 노드 라벨인 topology.kubernetes.io/*를 기반으로 각 사이드카에도 해당 지역성 정보를 부여한다.
워크로드에 직접적으로 istio-locality: {리전}.{존}과 같은 식으로 라벨을 달아도 지역 설정으로 인식된다.
만약 이런 정보를 얻을 수 없는 상태에서 지역적 로드밸런싱 세팅을 하게 될 경우, 이스티오는 엔보이에서 사용하는 방식을 따른다.[5]
세 가지 설정 방법이 있다.
- distribute - from에서 들어온 트래픽을 to로 보내는 비율 설정
- 참고로
enabled: true만 하고 아무 설정 안 넣으면 각 지역의 엔드포인트 개수 기준으로 ditsribute가 설정된다.
- 참고로
- failover - from의 엔드포인트가 unhealthy할 때 to로 보냄
- 전부 unhealthy 해야만 보내는 건 아니고 이건 엔보이의 priority에 기반하는데, 바로 아래 failoverPriority 참고.[6]
- failoverPriority - 리스트 별로 한 다운스트림에 대한 여러 업스트림의 라우팅 우선순위 등급(priority)을 매김
- 리스트 첫번째부터, 일치하지 않는 값이 나올 때까지 연속된 리스트의 개수가 곧 해당 엔드포인트의 우선순위가 된다.
- 엄밀하게는 역순으로, 모든 리스트가 매칭되는 엔드포인트가 0 순위이다.
- 위 예시에서 1,2,4 번째 원소가 매칭되는 엔드포인트가 있다면, 1,2만 기준으로 평가되어 2순위가 된다.
- 키 값쌍을 넣어 더 정밀하게 우선순위를 부과할 수도 있다.
- 이 등급 별로 구분 짓고 healthy한 엔드포인트 퍼센티지를 따져 트래픽을 분산한다.[7]
- 리스트 첫번째부터, 일치하지 않는 값이 나올 때까지 연속된 리스트의 개수가 곧 해당 엔드포인트의 우선순위가 된다.
이 설정들은 독점적이라 서로 같이 사용할 수 없다!
왜냐, 각각의 설정이 실제 엔보이에 적용될 때 충돌을 일으키기 때문이다.
- distribute - 업스트림의 상태를 따지지 않고 우직하게 들어온 기준으로 분산
- failover - 업스트림의 상태를 보고 한 쪽에서 다른 쪽으로 모든 트래픽을 옮김
- failoverPriority - 일단 업스트림을 등급을 매긴 후에, 상태를 보면서 조금씩 트래픽 분산
일단 distribute는 정적으로 비율을 설정하기에 당연히 health를 따지는 failover와 충돌한다.
여기에 failoverPriority는 다른 것과 다르게 아예 등급을 매겨버리기 때문에 설정 방식부터가 다르다.

참고로 기본 이스티오 전역 설정에 지역적 로드밸런싱은 세팅돼있다.[8]
outlierDetection
trafficPolicy:
connectionPool:
tcp:
maxConnections: 100
http:
http2MaxRequests: 1000
maxRequestsPerConnection: 10
outlierDetection:
consecutiveGatewayErrors: 2 # 기본적인 이상치 기준
splitExternalLocalOriginErrors: true # 로컬 오류와 업스트림 오류 구분할지
consecutiveLocalOriginFailures: 3 # 로컬 오류를 구분한다면 로컬에서 몇 번 에러날 때 제외할지
consecutive5xxErrors: 5 # http 한정 이상치 기준
interval: 10s
baseEjectionTime: 30s # 기본 제외 기간으로, 지수적 증가
maxEjectionPercent: 20 # 최대 제외 가능한 호스트 수
minHealthPercent: 50 # 이상치 탐지 중단할 최소 헬시 퍼센트
이상치 탐지를 통해 서킷 브레이커를 하는 필드.
연속적인 오류를 이상치 패턴으로 감지 - 이상치를 넘긴 호스트를 잠시 제외(ejection) - 일정 시간 후 재검증과 같은 식으로 동작한다.
이상치라고 탐지된 엔드포인트는 잠시 unhealthy 상태로 체크하고 로드밸런싱 풀에서 잠시 제외된다.
이것도 http, tcp 각각에 적용 가능하며, 가령 다음과 같은 식이다.
- http - 500에러가 날 때
- tcp - 커넥션 타임아웃이나 실패가 뜰 때
로컬 오류와 업스트림 오류를 구분한다는 것은 다음과 같은 식이다.
a에서 b로 가는 요청이 있고, a에서 타임아웃 기간을 1초로 잡았다.
이 타임아웃으로 인해 발생하는 오류와, 실제로 b가 뱉어내는 오류를 구분하고 싶다면 splitExternalLocalOriginErrors를 true 걸면 된다.
consecutiveGatewayErrors 필드는 http 에러도 이상치로 잡기 때문에 consecutive5xxErrors와 같이 쓴다면 조금 더 높게 잡는 것이 일반적이다.
maxEjectionPercent는 이상치로 둘 수 있는 최대 업스트림의 퍼센트를 나타내며, 이 이상을 넘어가면 이상치로 보이더라도 제외시키진 않는다.
minHealthPercent는 이상치 탐지를 활성화하는 최소 healthy 업스트림의 퍼센트를 나타낸다.
가령 이 값이 50으로 설정돼있는데 이상치 탐지를 하다보니 healthy한 업스트림이 50퍼 미만으로 내려가버린다면, 그냥 이상치 탐지가 완전히 중단되고 unhealthy 해도 트래픽을 날려버린다!
기본값은 0인데, 이 값은 이상치 탐지를 비활성화하지 않고 계속 활성화한다.
fortio
![]()
포르티오는 이스티오 개발진들이 네트워크 테스트를 하면서 만들었던 툴이 점차 고도화되면서 아예 하나의 오픈소스로 분할되어버린 부하 테스트 툴이다.[9]
go 언어로 만들어졌으며 경량으로 간단하게 테스트하기 좋다.
포르티오 자체가 하나의 툴이지만, 아예 이걸 언어 라이브러리로 추가해서 스크립트를 짜서 조금 더 고도화된 테스트를 하는 데에도 사용할 수 있다.
실습 진행
기본 환경 구성은 항상 동일하다.
docker run --name fortio --network host fortio/fortio server &
포르티오를 이용해 간단하게 부하를 줄 것이기 때문에 포르티오 서버를 띄워둔다.
커맨드를 로컬에 다운 받아서 실행하는 것도 가능한데, 나는 많이 쓸 명령어가 아닐 것 같다고 생각해서 그냥 컨테이너로 실행했다.
로컬호스트로 요청을 보내야 하기 때문에 호스트 네트워크를 써줘야 정상적으로 트래픽을 보낼 수 있다.

세팅이 제대로 되고 자시고도 없지만 아무튼 띄워지면 이렇게 웹 ui로도 접근이 가능해진다.
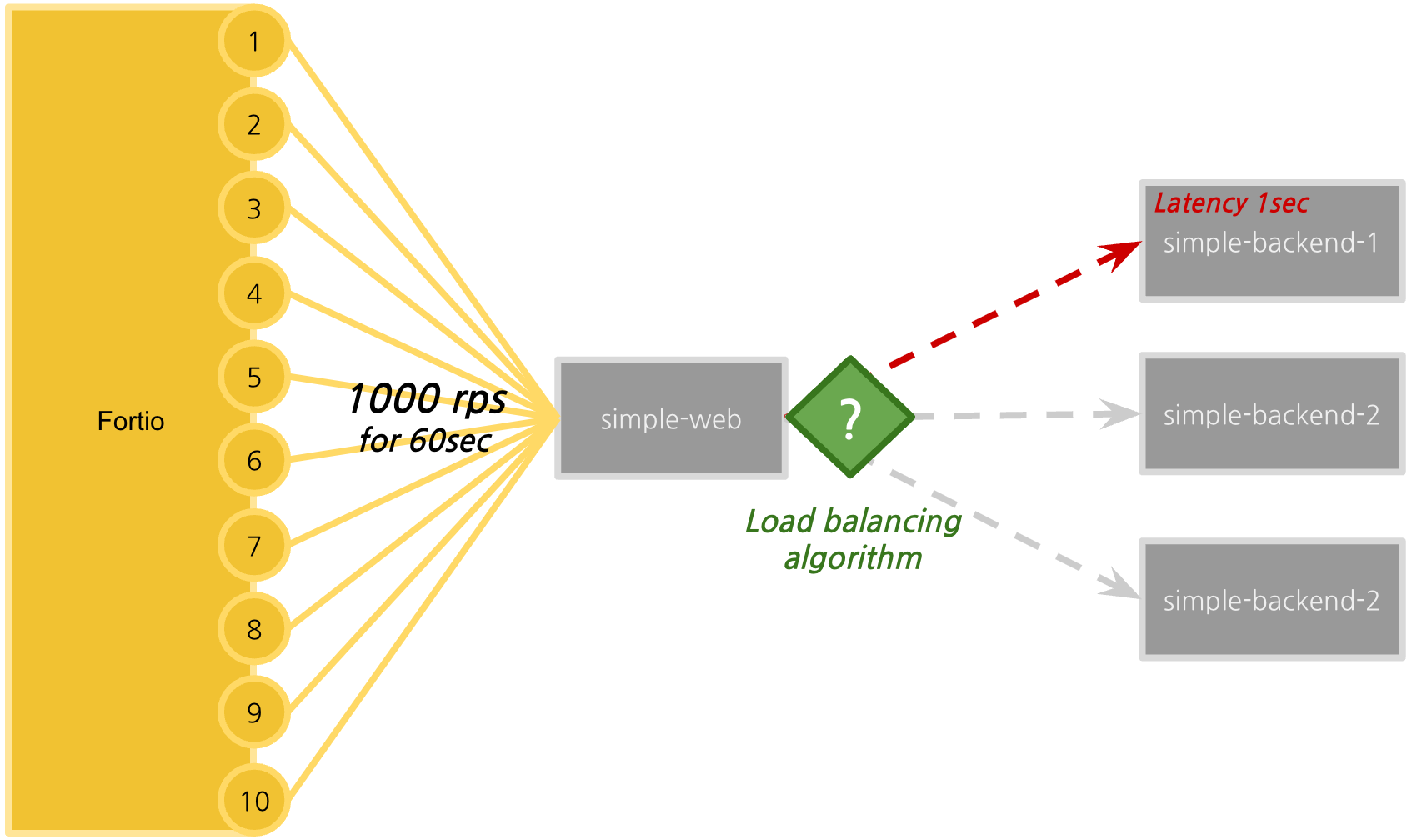
위 그림처럼 10개의 별도의 커넥션마다 60초 동안 초당 1000 rps를 날릴 것이다. [10]
각 로드밸런싱 알고리즘에 따라 어떤 결과가 나오는지 살펴보자.
클라이언트 로드밸런싱
kubectl apply -f ch6/simple-backend.yaml -n istioinaction
kubectl apply -f ch6/simple-web.yaml -n istioinaction
kubectl apply -f ch6/simple-web-gateway.yaml -n istioinaction
실습에 필요한 워크로드를 간단하게 배포한다.
apiVersion: networking.istio.io/v1alpha3
kind: Gateway
metadata:
name: simple-web-gateway
spec:
selector:
istio: ingressgateway
servers:
- port:
number: 80
name: http
protocol: HTTP
hosts:
- "simple-web.istioinaction.io"
---
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: simple-web-vs-for-gateway
spec:
hosts:
- "simple-web.istioinaction.io"
gateways:
- simple-web-gateway
http:
- route:
- destination:
host: simple-web
게이트웨이와 버츄얼 서비스는 매우 간단하게 세팅돼있다.

간단하게 두 버전의 백엔드가 있고, 2버전의 경우 레플리카가 2개인 상태이다.
SIMPLEWEB="simple-web.istioinaction.io"
while true; do curl -s http://$SIMPLEWEB:30000 --resolve "$SIMPLEWEB:30000:127.0.0.1" | jq ".upstream_calls[0].body" ; date "+%Y-%m-%d %H:%M:%S" ; sleep 1; echo; done
시각화 편의성을 위해 반복 접근을 해둔다.

보다시피, 예제에서는 각 버전에 대한 라벨을 표시해두지 않아서 그냥 latest로 정보가 표시된다.

각 디플로이먼트에 버전 정보를 명시해서 넣어주자.

1 버전은 파드가 하나고 2버전은 2개인 상태로 균등하게 분배되고 있어 얼추 33퍼, 66퍼 정도로 트래픽의 퍼센티지가 나오는 것을 확인할 수 있다.
istioctl pc endpoint simple-web-85d57c8486-msbwl --cluster "outbound|80||simple-backend.istioinaction.svc.cluster.local" -ojson |fx

웹에서 백엔드로 잡히는 엔드포인트는 3개로, 별 다른 설정은 되어있지 않다.
istioctl pc cluster simple-web-85d57c8486-msbwl --fqdn simple-backend.istioinaction.svc.cluster.local -ojson | fx

클러스터쪽 설정을 보면 로드밸런싱 정책을 확인할 수 있는데, LEAST_REQUEST로 돼있는 것을 볼 수 있다.
별다른 문제가 없는 이상 각 엔드포인트로 연결 요청이 공정하게 가게 된다.
kubectl apply -f ch6/simple-backend-delayed.yaml -n istioinaction
kubectl rollout restart deployment -n istioinaction simple-backend-1

본격적으로 실습을 하기 위해 백엔드 버전 1에는 지연 시간을 부과할 것이다.

이 세팅을 하면 버전 1로 가는 요청은 전부 1초 이상의 지연이 발생하게 된다.

코드를 보면 분산 값과 지연 시간을 기반으로 지연을 발생시키는 것을 확인할 수 있다.[11]

50분위에 대해서만 설정을 했지만, 다른 값들이 지정이 안 된다면 90분위, 99분위까지도 똑같이 세팅이 된다.
즉 그냥 버전 1로 가는 모든 요청에 지연이 발생한다고 봐도 무방하다.
라운드 로빈
apiVersion: networking.istio.io/v1beta1
kind: DestinationRule
metadata:
name: simple-backend-dr
spec:
host: simple-backend.istioinaction.svc.cluster.local
trafficPolicy:
loadBalancer:
simple: ROUND_ROBIN
로드밸런싱 정책을 수정해본다.
SIMPLEWEB="simple-web.istioinaction.io"
for in in {1..50}; do curl -s http://$SIMPLEWEB:30000 --resolve "$SIMPLEWEB:30000:127.0.0.1"| jq ".upstream_calls[0].body"; done | sort | uniq -c | sort -nr

간단하게 터미널로 각 백엔드의 호출 횟수를 확인해봐도 엔드포인트 별로 무작위로 호출된 것을 확인할 수 있다.

다시 클러스터 정보를 확인해보면 이번에는 로드밸런싱 정보가 없어진 것을 확인할 수 있다.
라운드 로빈 방식은 엔보이의 기본 로드밸런싱 정책으로 해당 방식으로 세팅하면 그냥 표시가 안 되는 것을 볼 수 있다.

이제 본격적으로 부하 테스트를 걸어본다.
- Title : roundrobin
- URL : http://simple-web.istioinaction.io:30000
- QPS : 1000
- Duration : 60s
- Threads : 10
- Jitter: Check
- No Catch-up : Uncheck
- Extra Headers
- User-Agent: fortio
- Host: simeple-web.istioinaction.io
- Load using
- resolve: 127.0.0.1
- Timeout : 2000ms
수정해준 부분은 이 정도이다.
uniform 세팅 시 부하 간 요청 간격이 동일해지고, jitter는 처음 알았는데 그냥 포아송 분포로 요청을 흩뿌린다고 한다.
No Catch up 세팅은 요청 측의 컴퓨팅 제한으로 인해 요청이 지연되더라도 기어코 남은 요청들을 전부 보내는 설정이다.
캐치업을 하면 각 초에 지정된만큼 요청을 보내지 못하더라도 이후 초에 지정된 만큼 요청을 날리기 위해 못다한 요청 수를 버린다.
이렇게 세팅하고 진행하자.

요청이 빗발친다..!

히스토그램으로 봤을 때 x축이 응답 시간, 해당하는 개수가 y축이다.
즉 요청 시간이 200ms 정도인 게 1000개 가랑, 1초 정도 걸리는 게 500개 가량 되는 것이다.
이는 위에서 본 분산 비율과 일치한다.
라운드 로빈의 경우 정직하게 모든 엔드포인트가 똑같은 수의 요청을 받게 하므로, 그만큼 정직하게 결과가 나올 수밖에 없다.
랜덤
apiVersion: networking.istio.io/v1beta1
kind: DestinationRule
metadata:
name: simple-backend-dr
spec:
host: simple-backend.istioinaction.svc.cluster.local
trafficPolicy:
loadBalancer:
simple: RANDOM
이번엔 랜덤으로 로드밸런싱해보자.

(같은 화면 아님..)
결과는 비슷하다.
랜덤의 경우에도 궁극적으로는 각 엔드포인트에 비슷하게 트래픽이 가기 때문에 달라지는 게 없다.
최소 연결
apiVersion: networking.istio.io/v1beta1
kind: DestinationRule
metadata:
name: simple-backend-dr
spec:
host: simple-backend.istioinaction.svc.cluster.local
trafficPolicy:
loadBalancer:
simple: LEAST_CONN
이제 처음에 세팅됐던 방식인 최소 연결 방식으로 진행해본다.

이번엔 확실하게 결과에 차이가 발생한다.

키알리로도 응답 속도가 빠른 버전 2로 기존보다 훨씬 더 많은 트래픽이 간 것을 확인할 수 있다.
버전 1의 경우 응답 지연이 있기 때문에 버전 1은 오랫동안 물려 있는 tcp 연결이 많다.
그렇기 때문에 응답이 빨리 돌아와서 새로운 커넥션을 만들 수 있는 버전 2로 트래픽이 몰리게 된다.

기존에는 75분위수부터 응답 시간이 1초 가량 나왔으나, 이제는 90분위수부터 1초가 찍힌다.
즉, 현재 클러스터는 최소한 75퍼센트 정도는 빠른 응답을 받아볼 수 있다는 뜻이렷다.
지역 기반 로드밸런싱
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: simple-web
name: simple-web
spec:
replicas: 1
selector:
matchLabels:
app: simple-web
template:
metadata:
labels:
app: simple-web
istio-locality: us-west1.us-west1-a
version: "v1"
spec:
...
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: simple-backend
name: simple-backend-1
spec:
replicas: 1
selector:
matchLabels:
app: simple-backend
template:
metadata:
labels:
app: simple-backend
istio-locality: us-west1.us-west1-a
version: "v1"
spec:
...
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: simple-backend
name: simple-backend-2
spec:
replicas: 2
selector:
matchLabels:
app: simple-backend
template:
metadata:
labels:
app: simple-backend
istio-locality: us-west1.us-west1-b
version: "v2"
spec:
...
이제 지역 기반 로드밸런싱을 수행해본다.
기본적으로는 노드에 달려진 라벨을 토대로 지역이 설정되지만, 위와 같이 파드 라벨에 istio-locality를 설정하는 것으로도 지역 설정을 할 수 있다.
현재 사용하고 있는 노드는 하나인 관계로, 이런 식으로 테스트를 해야 한다.
istioctl pc endpoint simple-web-5dd8b98b8c-8888v --cluster "outbound|80||simple-backend.istioinaction.svc.cluster.local" -ojson | fx

엔드포인트를 까보면 로컬리티에 리전과 존이 세팅된 것을 확인할 수 있다.
이제 이를 기반으로 로드밸런싱을 수행할 수 있게 된 것이다!
가중치 세팅 - 이스티오 표기 버그?
apiVersion: networking.istio.io/v1beta1
kind: DestinationRule
metadata:
name: simple-backend-dr
spec:
host: simple-backend.istioinaction.svc.cluster.local
trafficPolicy:
loadBalancer:
localityLbSetting:
distribute:
- from: us-west1/us-west1-a/*
to:
"us-west1/us-west1-a/*": 70
"us-west1/us-west1-b/*": 30
책의 내용이 조금 헷갈리게 돼있는데, 지역 로드밸런싱에서 가중치를 제어하는 방식은 이상치 탐지가 필요하지 않다.
정직하게 설정된 값을 기반으로 로드밸런싱을 수행하기 때문이다.

의도한 대로 트래픽의 가중치가 설정된 것을 확인할 수 있다.
이 세팅 정보는 어떻게 확인할 수 있는가?

일단 클러스터 정보로는 이걸 찾아볼 수 없다.

엔드포인트 설정 정보를 보더라도 weight 값은 그냥 1일 뿐, 가중치에 대한 값이 안 들어가는 것은 동일하다.
엔보이의 설정 방식에서 지역 가중치 로드밸런싱 설정은 클러스터 쪽에서 가중치 세팅이 명시돼야 하고, 이후에 각 지역성에 맞게 가중치가 명시돼야 한다고 나와있다.[12]
클러스터 쪽 설정은 분명하게 표시되고 있으나, 엔드포인트쪽에서는 제대로 설정이 표시되지 않는 것으로 추측된다.

정상적으로 세팅되려면 원래 이렇게 각 locality에 대해 load_balancing_weight 필드가 설정돼야 한다.[13]
아무래도 이스티오에서 locality 하위로 출력해야 할 정보를 출력하지 않고 있는 것으로 보인다.

애초에 지역 가중치 로드밸런싱에서는 priority 값이 먼저 선행해서 작용하는데, 이 값에 대한 표기도 뭉뚱그려서 세팅되는 것을 보면 의도적으로 이스티오에서 보여주지 않는 것일 수도 있긴 하다.
그러나 어느 측면에서든, 내가 세팅한 측면을 명확하게 모니터링하는 게 불가능하다는 것은 큰 페인포인트가 될 수 있다.
페일 오버
apiVersion: networking.istio.io/v1beta1
kind: DestinationRule
metadata:
name: simple-backend-dr
spec:
host: simple-backend.istioinaction.svc.cluster.local
trafficPolicy:
outlierDetection:
consecutive5xxErrors: 1
interval: 5s
baseEjectionTime: 30s
maxEjectionPercent: 100
이번에는 기본으로 활성화된 지역 로드밸런싱 기능을 써본다.
이스티오에서는 기본적으로 지역 로드밸런싱이 활성화돼있는데, 거의 failover처럼 동작한다.
가중치 제어 방식을 제외하면 모든 지역 기반 로드밸런싱은 이상치 탐지, 즉 헬스체크를 필요로 한다.

그래서 보다시피 이상치 탐지 설정만 걸어두어도 지역 기반 로드밸런싱이 이뤄지게 된다.
일단 같은 지역으로 트래픽을 보내고 보는 것이다.

클러스터 정보를 보면 이 설정을 조금 더 제대로 확인할 수 있다.
이상치 탐지에 대한 세팅이 이뤄지고 commonLbConfig 필드에는 health 기반 설정이 들어갔다.
근데 참고로 사용자가 직접 세팅하는 지역 기반 로드밸런싱과는 조금 다르다.
- name: "SERVER_TYPE"
value: "http"
- name: "NAME"
value: "simple-backend"
- name: "MESSAGE"
value: "Hello from simple-backend-1"
- name: "ERROR_TYPE"
value: "http_error"
- name: "ERROR_RATE"
value: "1"
- name: "ERROR_CODE"
value: "500"
그렇다면 에러를 발생시키면 제대로 다른 지역으로 트래픽이 가는지도 확인해보자.
버전 1에 100퍼센트 에러를 발생시킨다.

기다리다 보면 v2로 트래픽이 거의 다 옮겨간 것이 보인다.
기본적으로 v1에 트래픽을 보내지만 에러가 발생하여 이를 이상치로 판단, v1으로 향하는 엔드포인트는 잠시 비활성화된다.
그리고 v2로 트래픽을 보내기 시작하는데, 그럼에도 계속 v2로만 보내는 건 아니고 비활성화 기간이 지나 다시 트래픽을 보내긴 하기 때문에 계속 한번씩 v1으로 트래픽이 가서 최종적으로 이런 모습이 나오게 된다.

엔드포인트를 보면 failedOutlierCheck가 된 것을 볼 수 있는데, 이게 이상치로 판명났다는 뜻이다.
아래 Headth는 EDS 설정으로 추적이 되고 있다는 것을 뜻한다.
최소한 서비스 메시 내에서 해당 엔드포인트가 추적되고 있다는 것을 명시하는 포인트이다.

이 정보는 json으로 뽑지 않고 그냥 보는 게 조금 더 보기 쉽다.
apiVersion: networking.istio.io/v1beta1
kind: DestinationRule
metadata:
name: simple-backend-dr
spec:
host: simple-backend.istioinaction.svc.cluster.local
trafficPolicy:
outlierDetection:
consecutive5xxErrors: 1
interval: 5s
baseEjectionTime: 30s
maxEjectionPercent: 100
loadBalancer:
localityLbSetting:
failover:
- from: us-west1.us-west1-b
to: us-west1.us-west1-a
마지막으로, 정말 failover로 세팅을 해본다.
혹시 failover 설정을 명시하면 기존 설정이 완전히 덮어쓰여지지 않을까 해서 거꾸로 된 방향으로만 설정했다.

그러나 동작 방식에는 아무런 변함이 없다.
기본적으로는 같은 지역으로 가고, 이상치 탐지 시에만 다른 지역으로 가고 있다.

클러스터 설정을 보면 localityWeightedLbConfig 설정이 또 들어갔다.
기본 활성화된 이스티오의 지역 기반 로드밸런싱과, 사용자가 설정하는 설정이 조금 다르다는 것을 알 수 있는 대목이다.
결론
이스티오는 분명 어렵지만 그럼에도 사용할 메리트로서 가장 크게 다가오는 부분이 이런 네트워크에 안정성을 부여할 수 있는 다양한 기능이 아닐까 싶다.
이번에 공부하면서 지역 기반 로드밸런싱에 대해서 조금 더 깊게 생각해볼 계기를 가질 수 있었다.
이전에는 무조건 가까운 지역으로 트래픽을 보내는 게 좋다고만 생각했는데, 오히려 지나치게 단순한 방식은 부하를 야기할 수 있다.
이런 생각이 든 후에는 가까울 수록 트래픽의 가중치를 높이는 방법이 있겠다고 생각했으나, 막상 이스티오에서는 그러한 기능을 지원하지 않는다는 것을 알게 됐다.
이건 심지어 쿠버네티스의 서비스에서도 마찬가지로 지원하지 않는 방식으로, 기본적으론 가중치가 아니라 근접한 지역에 우선순위를 두는 식으로 세팅을 많이 한다.
이전 글, 다음 글
다른 글 보기
| 이름 | index | noteType | created |
|---|---|---|---|
| 1W - 서비스 메시와 이스티오 | 1 | published | 2025-04-10 |
| 1W - 간단한 장애 상황 구현 후 대응 실습 | 2 | published | 2025-04-10 |
| 1W - Gateway API를 활용한 설정 | 3 | published | 2025-04-10 |
| 1W - 네이티브 사이드카 컨테이너 이용 | 4 | published | 2025-04-10 |
| 2W - 엔보이 | 5 | published | 2025-04-19 |
| 2W - 인그레스 게이트웨이 실습 | 6 | published | 2025-04-17 |
| 3W - 버츄얼 서비스를 활용한 기본 트래픽 관리 | 7 | published | 2025-04-22 |
| 3W - 트래픽 가중치 - flagger와 argo rollout을 이용한 점진적 배포 | 8 | published | 2025-04-22 |
| 3W - 트래픽 미러링 패킷 캡쳐 | 9 | published | 2025-04-22 |
| 3W - 서비스 엔트리와 이그레스 게이트웨이 | 10 | published | 2025-04-22 |
| 3W - 데스티네이션 룰을 활용한 네트워크 복원력 | 11 | published | 2025-04-26 |
| 3W - 타임아웃, 재시도를 활용한 네트워크 복원력 | 12 | published | 2025-04-26 |
| 4W - 이스티오 메트릭 확인 | 13 | published | 2025-05-03 |
| 4W - 이스티오 메트릭 커스텀, 프로메테우스와 그라파나 | 14 | published | 2025-05-03 |
| 4W - 오픈텔레메트리 기반 트레이싱 예거 시각화, 키알리 시각화 | 15 | published | 2025-05-03 |
| 4W - 번외 - 트레이싱용 심플 메시 서버 개발 | 16 | published | 2025-05-03 |
| 5W - 이스티오 mTLS와 SPIFFE | 17 | published | 2025-05-11 |
| 5W - 이스티오 JWT 인증 | 18 | published | 2025-05-11 |
| 5W - 이스티오 인가 정책 설정 | 19 | published | 2025-05-11 |
| 6W - 이스티오 설정 트러블슈팅 | 20 | published | 2025-05-18 |
| 6W - 이스티오 컨트롤 플레인 성능 최적화 | 21 | published | 2025-05-18 |
| 8W - 가상머신 통합하기 | 22 | published | 2025-06-01 |
| 8W - 엔보이와 iptables 뜯어먹기 | 23 | published | 2025-06-01 |
| 9W - 앰비언트 모드 구조, 원리 | 24 | published | 2025-06-07 |
| 9W - 앰비언트 헬름 설치, 각종 리소스 실습 | 25 | published | 2025-06-07 |
| 7W - 이스티오 메시 스케일링 | 26 | published | 2025-06-09 |
| 7W - 엔보이 필터를 통한 기능 확장 | 27 | published | 2025-06-09 |
관련 문서
| 이름 | noteType | created |
|---|---|---|
| Istio Gateway | knowledge | 2025-04-16 |
| Istio ServiceEntry | knowledge | 2025-04-17 |
| Istio VirtualService | knowledge | 2025-04-21 |
| Istio DestinationRule | knowledge | 2025-04-21 |
| Istio Sidecar | knowledge | 2025-05-13 |
| Istio ProxyConfig | knowledge | 2025-05-17 |
| 2W - 인그레스 게이트웨이 실습 | published | 2025-04-17 |
| 3W - 버츄얼 서비스를 활용한 기본 트래픽 관리 | published | 2025-04-22 |
| 3W - 트래픽 가중치 - flagger와 argo rollout을 이용한 점진적 배포 | published | 2025-04-22 |
| 3W - 트래픽 미러링 패킷 캡쳐 | published | 2025-04-22 |
| 3W - 서비스 엔트리와 이그레스 게이트웨이 | published | 2025-04-22 |
| 3W - 데스티네이션 룰을 활용한 네트워크 복원력 | published | 2025-04-26 |
| 3W - 타임아웃, 재시도를 활용한 네트워크 복원력 | published | 2025-04-26 |
| 6W - 이스티오 컨트롤 플레인 성능 최적화 | published | 2025-05-18 |
| 7W - 이스티오 메시 스케일링 | published | 2025-06-09 |
| E-이스티오 컨트롤 플레인 성능 최적화 | topic/explain | 2025-05-18 |
| E-이스티오 DNS 프록시 동작 | topic/explain | 2025-06-01 |
| E-이스티오 메시 스케일링 | topic/explain | 2025-06-08 |
참고
https://www.envoyproxy.io/docs/envoy/latest/intro/arch_overview/upstream/load_balancing/load_balancers#weighted-least-request ↩︎
https://www.eecs.harvard.edu/~michaelm/postscripts/handbook2001.pdf ↩︎
https://www.envoyproxy.io/docs/envoy/latest/intro/arch_overview/upstream/load_balancing/locality_weight ↩︎
https://istio.io/latest/docs/tasks/traffic-management/locality-load-balancing/failover/ ↩︎
https://www.envoyproxy.io/docs/envoy/latest/intro/arch_overview/upstream/load_balancing/priority ↩︎
https://istio.io/latest/docs/reference/config/istio.mesh.v1alpha1/ ↩︎
https://netpple.github.io/docs/istio-in-action/Istio-ch6-resilience ↩︎
https://www.envoyproxy.io/docs/envoy/latest/intro/arch_overview/upstream/load_balancing/locality_weight ↩︎
https://github.com/envoyproxy/examples/blob/main/locality-load-balancing/envoy.yaml ↩︎